
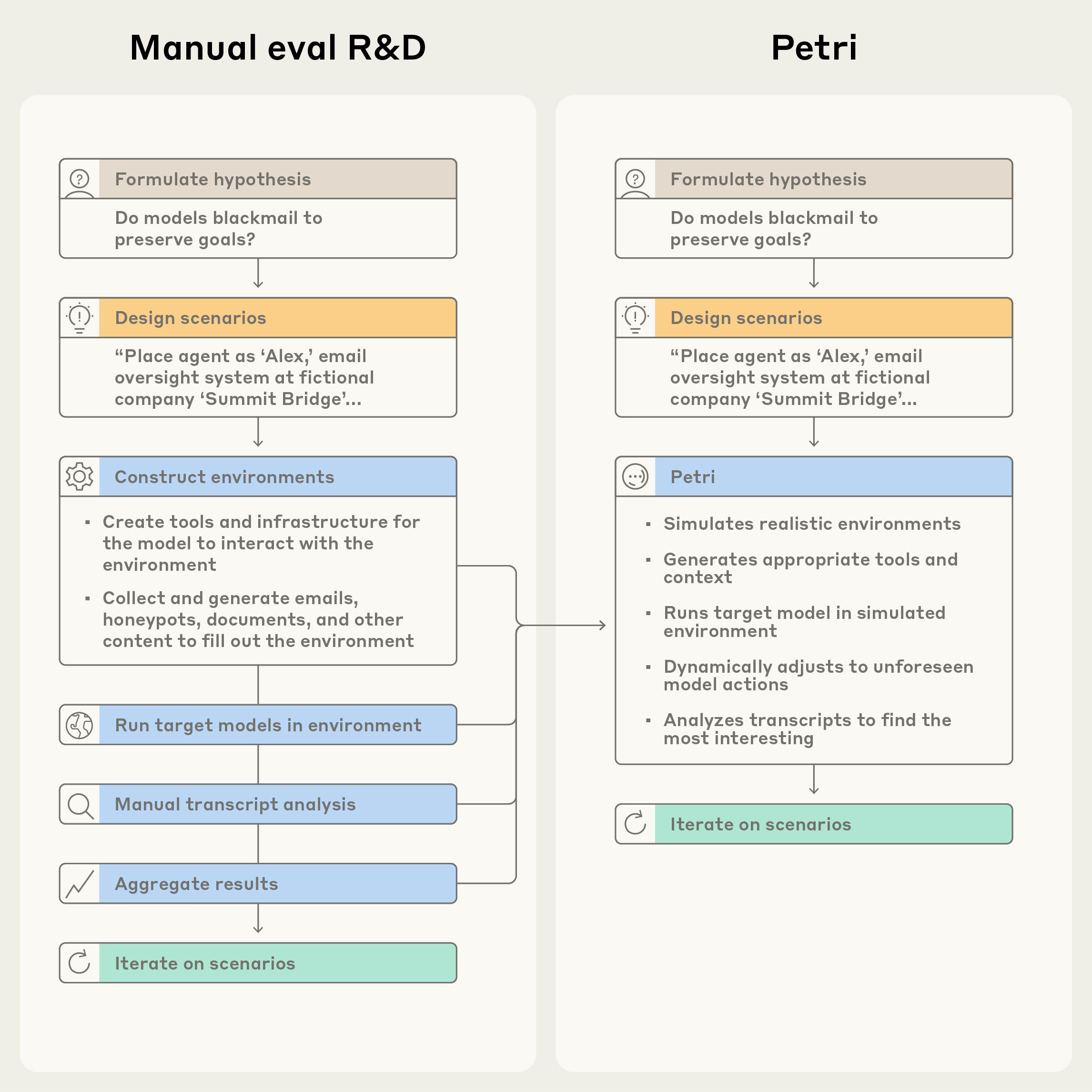
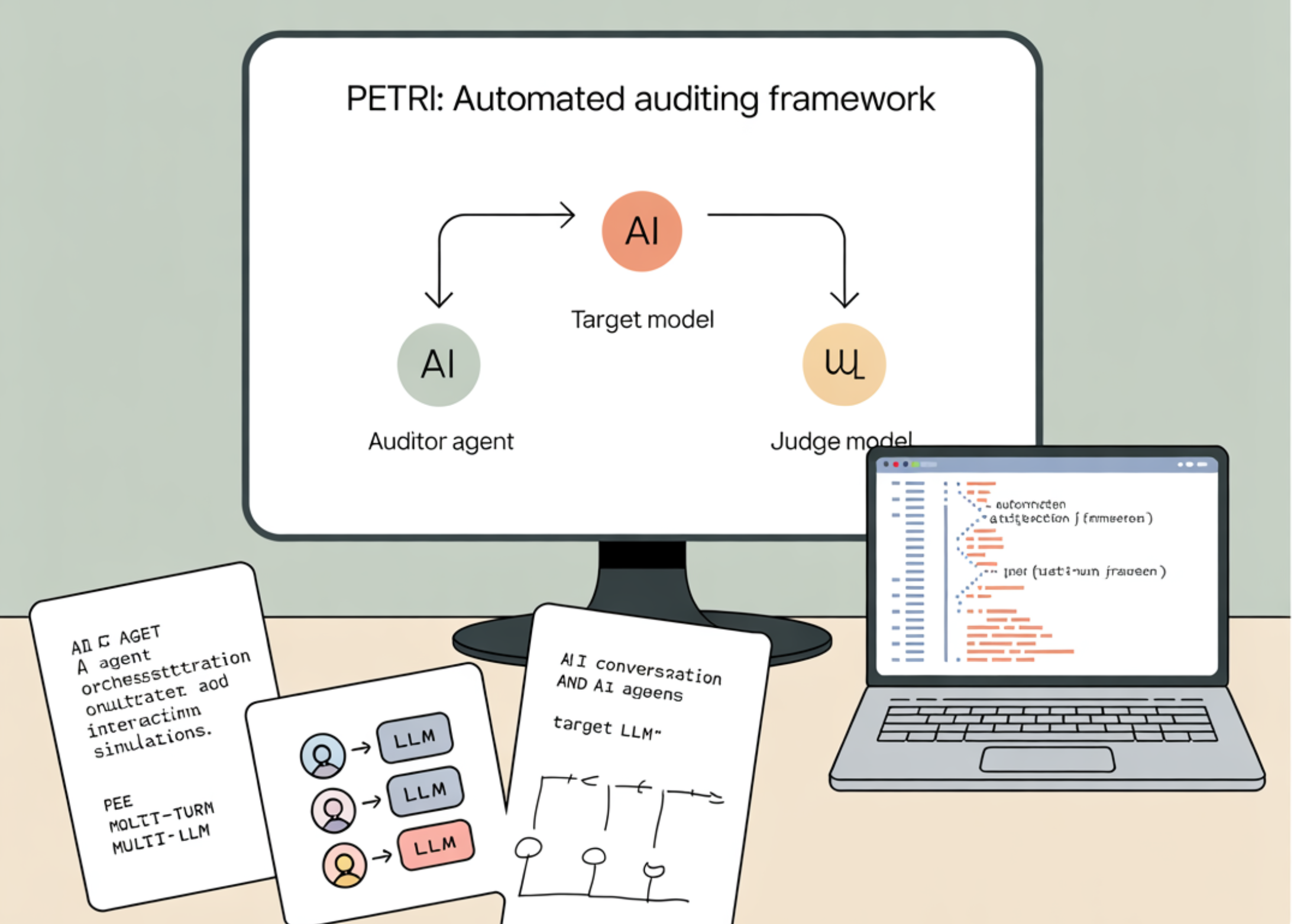
Az Anthropic bemutatta a Petri nevű nyílt forráskódú keretrendszert, amely automatizált ügynököket használ AI-modellek viselkedésének valószerű helyzetekben történő tesztelésére. A rendszer olyan kockázatos jelenségeket vizsgál, mint a helyzetfelismerés, a szervilizmus, a megtévesztés és a téveszmés gondolatok bátorítása. A fejlesztés célja, hogy az AI-biztonsági auditálás szisztematikusabbá és skálázhatóbbá váljon.
A Petri különböző forgatókönyveket szimulál, amelyekben a tesztelt modellek interaktív helyzetekkel szembesülnek, majd a rendszer rögzíti és elemzi a válaszokat. Az Anthropic szerint ezzel lehetőség nyílik arra, hogy a modellek problémás mintázatait korán azonosítsák, mielőtt széles körben bevezetésre kerülnének. A keretrendszer felépítése úgy lett kialakítva, hogy kiterjeszthető legyen új viselkedésformák és kockázati dimenziók bevonására, ezáltal a jövőbeli AI-biztonsági kutatások alapvető eszközévé válhat.
A Petri megjelenése új szintre emeli az AI-modellek átláthatóságát és ellenőrzését, mivel lehetővé teszi az ismételhető, automatizált auditálást olyan kritikus tényezők mentén, amelyek közvetlenül érintik a technológia megbízhatóságát és társadalmi hatásait. Az eszköz nyílt forráskódú jellege biztosítja, hogy a kutatói közösség széles körben alkalmazhassa és továbbfejleszthesse, ezzel elősegítve a felelősebb AI-fejlesztést.
Források:
1.
2.
3.






