A Google DeepMind 2024 decemberében mutatta be a FACTS Grounding rendszert, amely forradalmasíthatja a nagy nyelvi modellek (LLM-ek) tényszerűségének értékelését. A benchmark elsőként teszi lehetővé a hosszú, akár 32 ezer tokenes dokumentumokra épülő válaszok automatizált ellenőrzését, különös tekintettel a forráshűségre és a tényszerűségre.
A rendszer különlegessége a kétszintű értékelési folyamatban és az átfogó tesztkészletben rejlik. A 860 nyilvános és 859 privát teszteset öt kulcsfontosságú területet fed le: orvosi (29%), jogi (22,2%), internet/technológiai (19,2%), pénzügyi (18,1%) és kiskereskedelmi (11,4%) témákat. Az értékelés első fázisában a rendszer kiszűri azokat a válaszokat, amelyek nem felelnek meg a felhasználói kérésnek, majd a második fázisban elemzi a fennmaradó válaszok tényszerűségét a forrásszöveghez viszonyítva. A megbízhatóság érdekében három vezető nagy nyelvi modell - Gemini 1.5 Pro, GPT-4o és Claude 3.5 Sonnet - együttes döntését használják, mivel a kutatók kimutatták, hogy a modellek általában 3,23%-kal kedvezőbben értékelik saját kimeneteiket más modellekéhez képest.
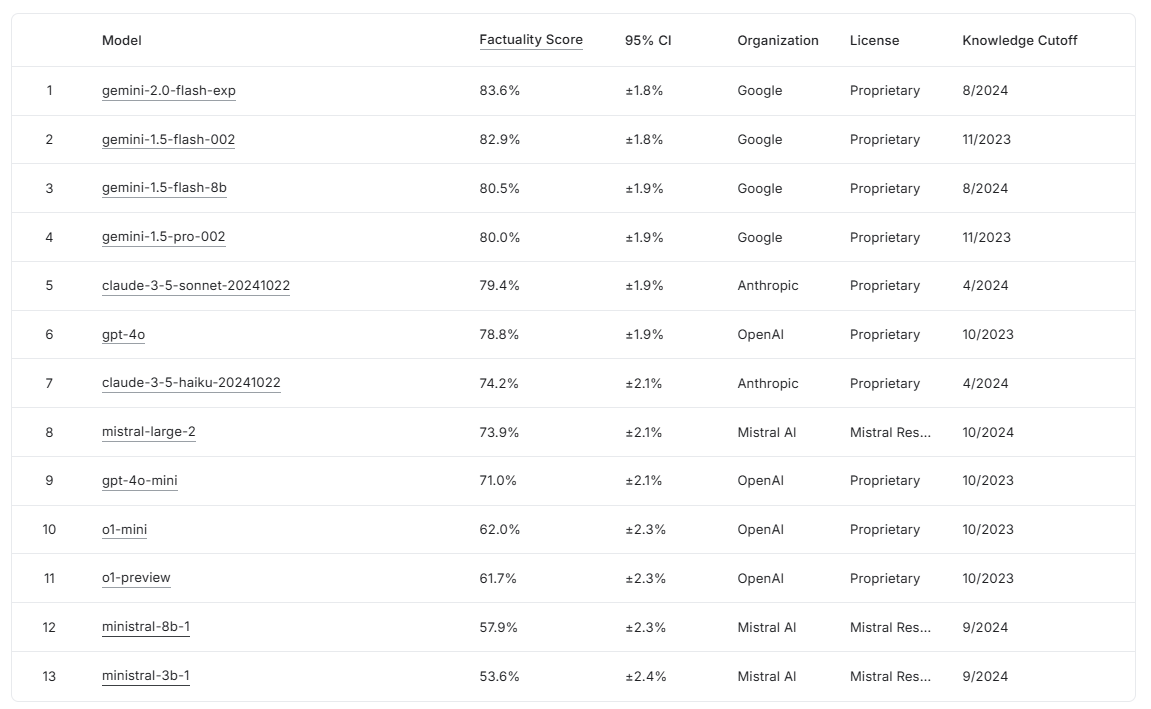
A kezdeti tesztek izgalmas eredményeket hoztak: a Gemini 2.0 Flash Experimental érte el a legjobb teljesítményt 83,6%-os pontszámmal, szorosan követte a Gemini 1.5 Flash (82,9%) és a Gemini 1.5 Pro (80,0%). Figyelemre méltó, hogy a nem megfelelő válaszok kiszűrése után a végső pontszámokban 1-5%-os csökkenés volt tapasztalható, ami jelzi a szigorú értékelési kritériumokat. A benchmark szabadon hozzáférhető a Kaggle platformon (www.kaggle.com/facts-leaderboard), így bármely kutató vagy fejlesztő tesztelheti saját modelljét. A rendszer különösen hasznos lehet olyan területeken, ahol kritikus fontosságú a generált szövegek pontossága és forráshűsége, például az orvosi dokumentációk vagy jogi szövegek automatizált feldolgozásában.
Források:
DeepMind's research paper on evaluating factual consistency in AI-generated text.