
Az "Identification of social scientifically relevant topics in an interview repository: A natural language processing experiment" című tanulmány egy úttörő kísérletet mutat be a társadalomtudományi kvalitatív adatok automatizált feldolgozására. A Társadalomtudományi Kutatóközpont Kutatási Dokumentációs Központja (TK KDK) és a Számítástechnikai és Automatizálási Kutatóintézet (SZTAKI) közös projektje 2020-ban indult, hogy mesterséges intelligencia segítségével tegye kereshetőbbé a társadalomtudományi interjúarchívumokat.
A szerzők (Gárdos et al. 2023) 39 interjút (összesen 1183 oldalt) választottak ki a gépi tanulás teszteléséhez, amelyből 21 interjú került a végleges tanulókészletbe. A kiválasztott anyagok között narratív interjúk, mélyinterjúk, félig strukturált interjúk és fókuszcsoportos beszélgetések is szerepeltek. Az öt tesztelt automatikus témafelismerési módszer közül a legjobb eredményt a SZTAKI által fejlesztett módszer érte el, amely a kulcsszavakhoz rendelt tárgyszavak alapján végzett elemzést, kiemelkedő F1-pontosságot mutatva. Szorosan mögötte az NN-ensemble hibrid megközelítés következett, amely az Omikuji és TF-IDF algoritmusok 3:1 arányú kombinációján alapult.
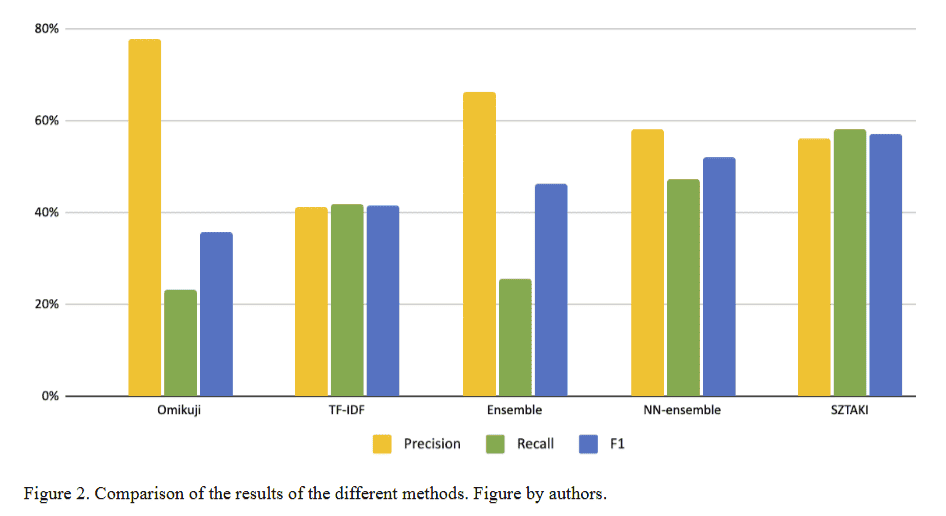
A kifejlesztett rendszer alapja egy 220 elemű társadalomtudományi tezaurusz, amely az European Language Social Science Thesaurus (ELSST) nemzetközi fogalomtár magyarra lefordított kifejezéseit, valamint 48 új, kifejezetten a magyar társadalmi és történelmi kontextusra jellemző fogalmat tartalmaz. Ilyen például a "rendszerváltás", "államosítás" vagy a "romafóbia". Ezáltal lehetővé válik a társadalomtudományi interjúk hatékonyabb kereshetősége és elemzése.
Források:
Gárdos, J., Egyed-Gergely, J., Horváth, A., Pataki, B., Vajda, R. és Micsik, A. (2023) Identification of social scientifically relevant topics in an interview repository: A natural language processing experiment, DOI: 10.1108/JD-12-2022-0269





