
A generatív mesterséges intelligencia (generatív MI vagy GenAI) eszközök a mesterséges intelligencia (MI) algoritmusok egy feltörekvő ágát képviselik (Tan et al. 2024, 168). Ellentétben a hagyományos MI-modellekkel, amelyek adatokat kategorizálnak vagy előrejelzéseket készítenek mintázatok alapján (Turchi et al. 2023, 35), a generatív MI a meglévő adatok egyszerű elemzésén túl képes felhasználói utasítások (prompt) alapján új, szintetikus tartalmak előállítására (Feuerriegel et al. 2024, 112). Ian Goodfellow, a generatív versengő hálózatok (Generative Adversarial Network, GAN) megalkotójának és a gépi tanulás egyik úttörő kutatójának megfogalmazásában a generatív modellek a gépi kreativitás egyik legfontosabb eszközei, amelyek lehetővé teszik a gépek számára, hogy túllépjenek a korábban látottakon, és valami újat hozzanak létre (Bordas et al. 2024, 427).
A generatív MI az intelligencia automatizált konstrukcióját tanulmányozó tudomány (Van Der Zant, Kouw, & Schomaker 2013, 113). Olyan modellek összessége, amelyek célja, hogy megtanulják az előtanításhoz használt adathalmaz alapszintű eloszlását, és olyan új adatpontokat generáljanak, amelyek ugyanezt az eloszlást követik (Goodfellow et al. 2014, 139). A megtanult mintázatok alapján rugalmas tartalomelőállítást tesz lehetővé különböző modalitásokban (például szöveg, audio, kép, videó vagy kód formájában), amelyekbe könnyen beleillik különféle feladatok széles köre.
Korábban az ilyen modellek jellemzően egyetlen modalitásra korlátozódtak (unimodal), vagyis egy adott típusú tartalom feldolgozására és generálására voltak alkalmasak, mint például az OpenAI GPT-3 modellje, amely kizárólag szöveges bemenetekkel dolgozott és szöveges válaszokat generált. A legújabb fejlesztések révén azonban megjelentek a multimodális (multimodal) modellek, amelyek egyszerre több eltérő formátumú tartalom feldolgozására és generálására is képesek (Banh & Strobel 2023, 7). Ilyen például az OpenAI GPT-4 multimodális verziója, amely szöveges és vizuális adatokat is képes kezelni, valamint ezek kombinációjával tartalmat létrehozni. Az unimodális és multimodális modellek működését az alábbi ábra szemlélteti.
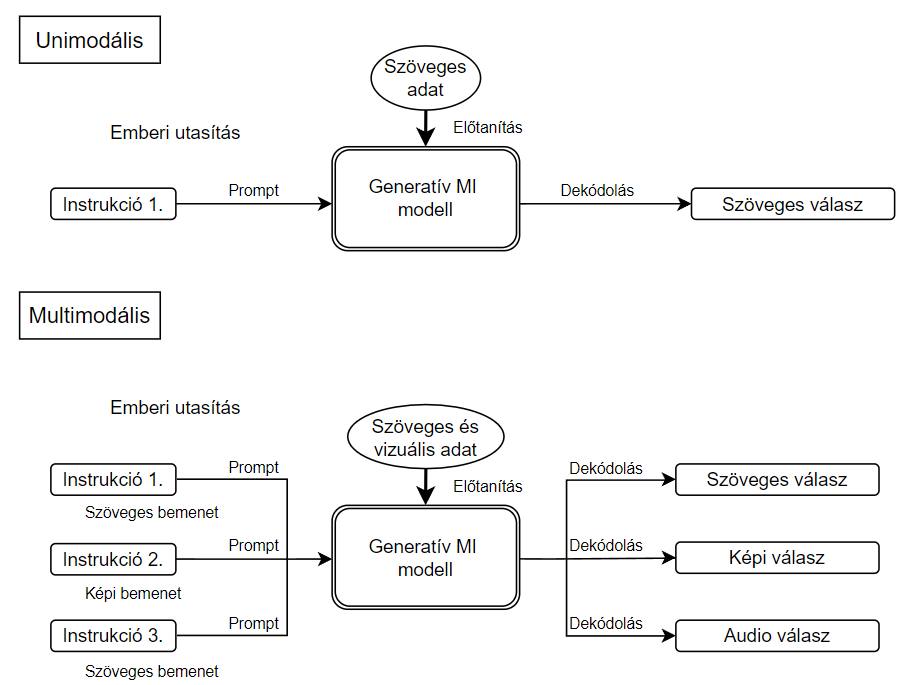
Bár kevésbé elterjedtek, léteznek keresztmodalitású (cross-modal) modellek is, amelyek különböző modalitások közötti adatátalakításra specializálódtak (Zhang et al. 2021). Ezek a modellek például lehetővé teszik szövegből képek generálását, ahogy azt a DALL-E teszi vagy képekből szöveges leírások készítését, amely a CLIP modell egyik kiemelkedő képessége. Ezen modellek különösen fontos szerepet játszanak olyan területeken, mint a vizuális kérdésmegértés (Visual Question Answering, VQA) a szöveg-alapú képalkotás (text-to-image generation) vagy a multimodális információkeresés.
Felhasznált irodalom:
1. Banh, Leonardo, and Gero Strobel. 2023. ‘Generative Artificial Intelligence’. Electronic Markets 33 (1): 63. doi:10.1007/s12525-023-00680-1 – ^ Vissza
2. Bordas, Antoine, Pascal Le Masson, Maxime Thomas, and Benoit Weil. 2024. ‘What Is Generative in Generative Artificial Intelligence? A Design-Based Perspective’. Research in Engineering Design 35 (4): 427–43. doi:10.1007/s00163-024-00441-x – ^ Vissza
3. Feuerriegel, Stefan, Jochen Hartmann, Christian Janiesch, and Patrick Zschech. 2024. ‘Generative AI’. Business & Information Systems Engineering 66 (1): 111–26. doi:10.1007/s12599-023-00834-7 – ^ Vissza
4. Goodfellow, Ian J., Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. 2014. ‘Generative Adversarial Networks’. arXiv. doi:10.48550/ARXIV.1406.2661 – ^ Vissza
5. Hariri, Walid. 2023. ‘Unlocking the Potential of ChatGPT: A Comprehensive Exploration of Its Applications, Advantages, Limitations, and Future Directions in Natural Language Processing’. arXiv. doi:10.48550/ARXIV.2304.02017 – ^ Vissza
6. Tan, Yue Hern, Hui Na Chua, Yeh-Ching Low, and Muhammed Basheer Jasser. 2024. ‘Current Landscape of Generative AI: Models, Applications, Regulations and Challenges’. In 2024 IEEE 14th International Conference on Control System, Computing and Engineering (ICCSCE), 168–73. Penang, Malaysia: IEEE. doi:10.1109/ICCSCE61582.2024.10696569 – ^ Vissza
7. Turchi, Tommaso, Silvio Carta, Luciano Ambrosini, and Alessio Malizia. 2023. ‘Human-AI Co-Creation: Evaluating the Impact of Large-Scale Text-to-Image Generative Models on the Creative Process’. In End-User Development, edited by Lucio Davide Spano, Albrecht Schmidt, Carmen Santoro, and Simone Stumpf, 13917:35–51. Lecture Notes in Computer Science. Cham: Springer Nature Switzerland. doi:10.1007/978-3-031-34433-6_3 – ^ Vissza
8. Van Der Zant, Tijn, Matthijs Kouw, and Lambert Schomaker. 2013. ‘Generative Artificial Intelligence’. In Philosophy and Theory of Artificial Intelligence, edited by Vincent C. Müller, 5:107–20. Studies in Applied Philosophy, Epistemology and Rational Ethics. Berlin, Heidelberg: Springer Berlin Heidelberg. doi:10.1007/978-3-642-31674-6_8 – ^ Vissza
9. Zhang, Han, Jing Yu Koh, Jason Baldridge, Honglak Lee, and Yinfei Yang. 2021. ‘Cross-Modal Contrastive Learning for Text-to-Image Generation’. arXiv. doi:10.48550/ARXIV.2101.04702 – ^ Vissza





